Building a Data Visualization Dashboard in Racket
When experimenting with a new data visualization or data analysis method, it is simpler to write a prototype as a separate application, to evaluate if it is worthwhile investing the effort of adding a full feature to ActivityLog2, this post illustrates the process used to write a “training load” dashboard application in Racket.
While it has a variety of ways to visualize training data, ActivityLog2 is not extensible, instead, the user must choose between a predefined number of plots on which they can adjust various input parameters. The predefined plots allows analyzing training data from a wide variety of angles, and it has been useful for me for a long time, but it does not cover everything, and, most importantly, it does not allow exploring new ideas. This is by design: ActivityLog2 an application needs to be reliable and can be used on a daily basis.
This post is not about training methods or their worth, but simply about visualizing an idea to see if it provides any value. In this case, the idea is that to reduce the risk of injury while training one needs to make sure that each week he or she can train between 20% and 60% more than the previous 4 week average. To check how this method would work, it is worth plotting the data and get a visual image, as seen below.
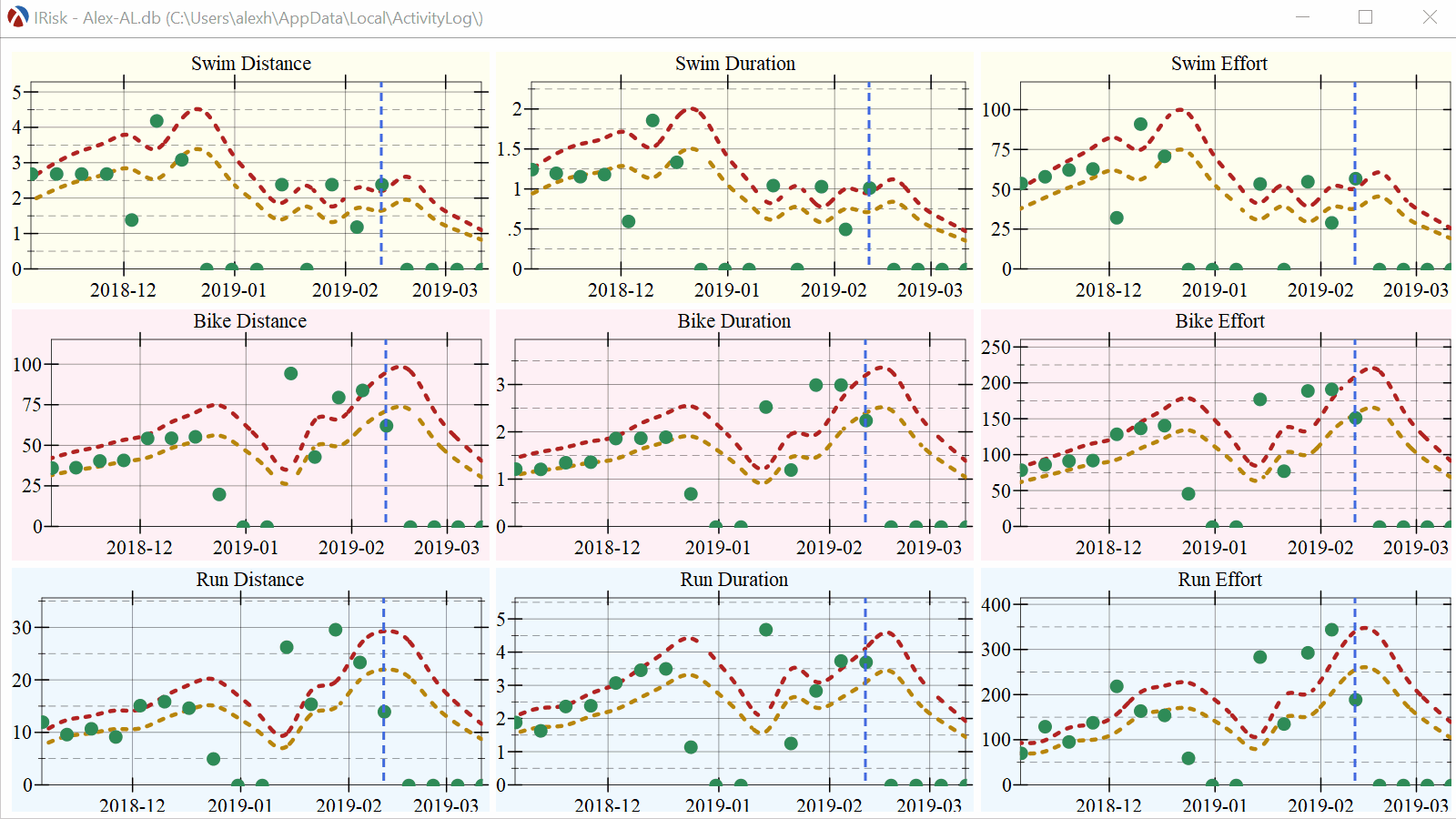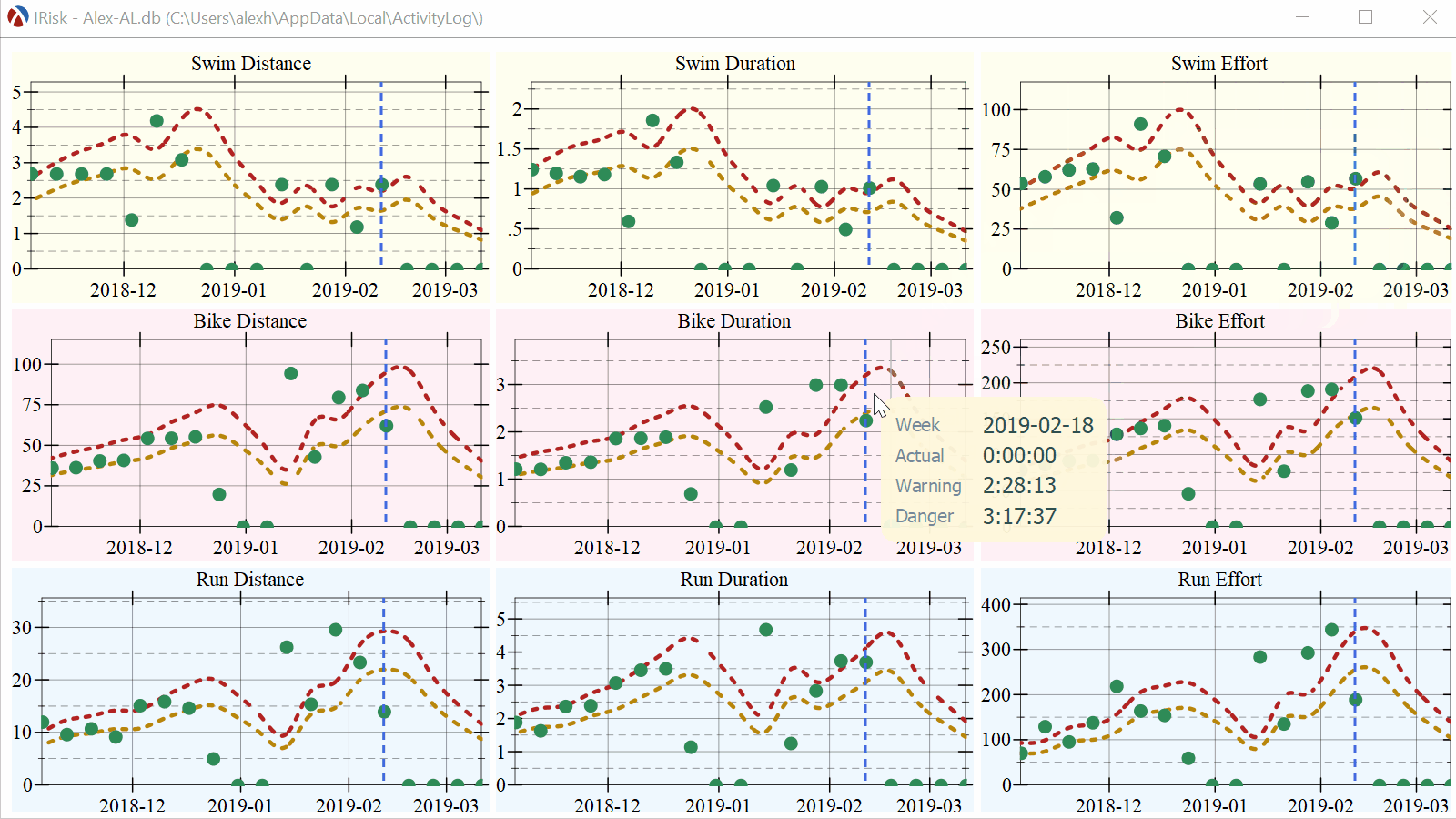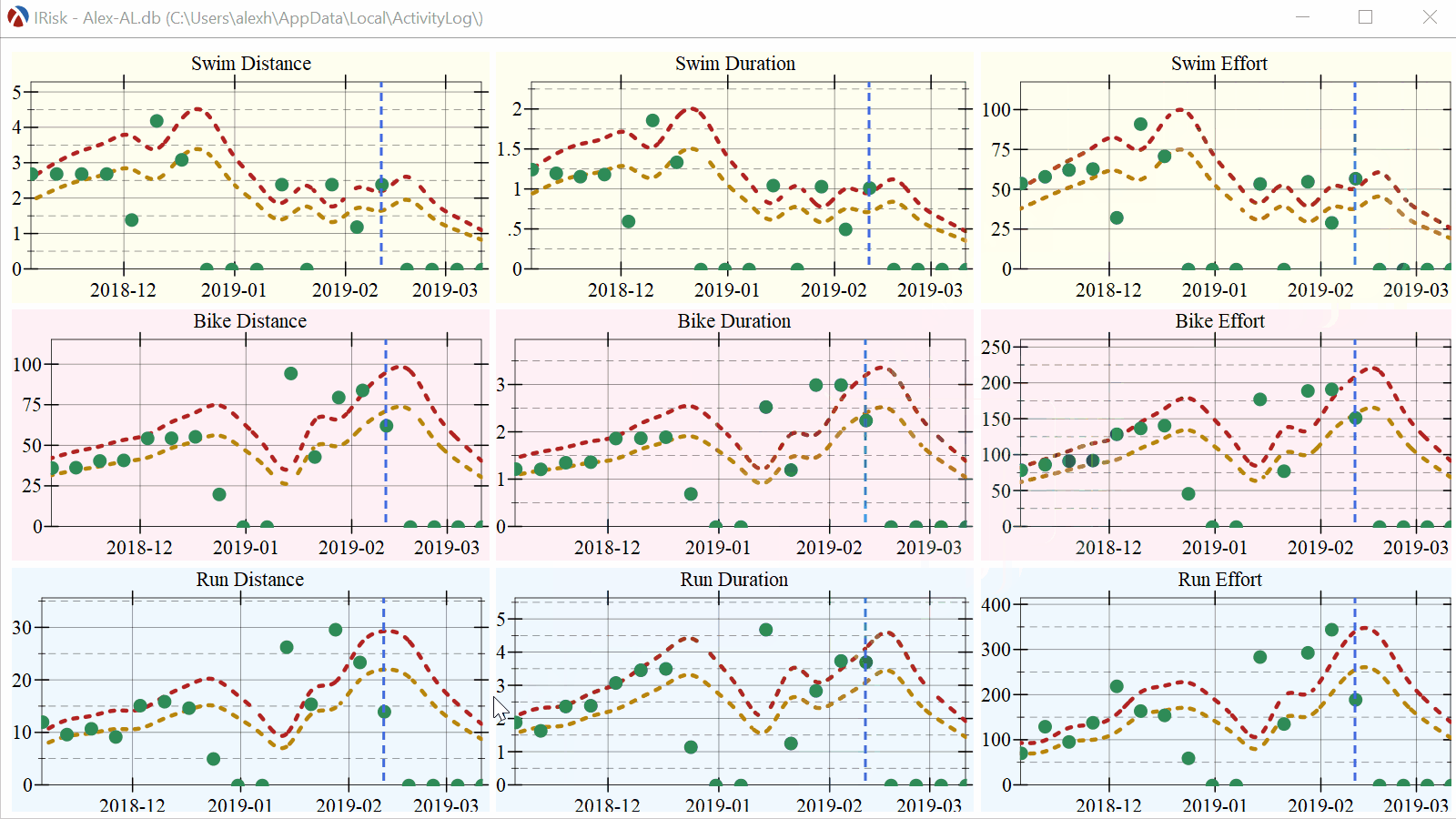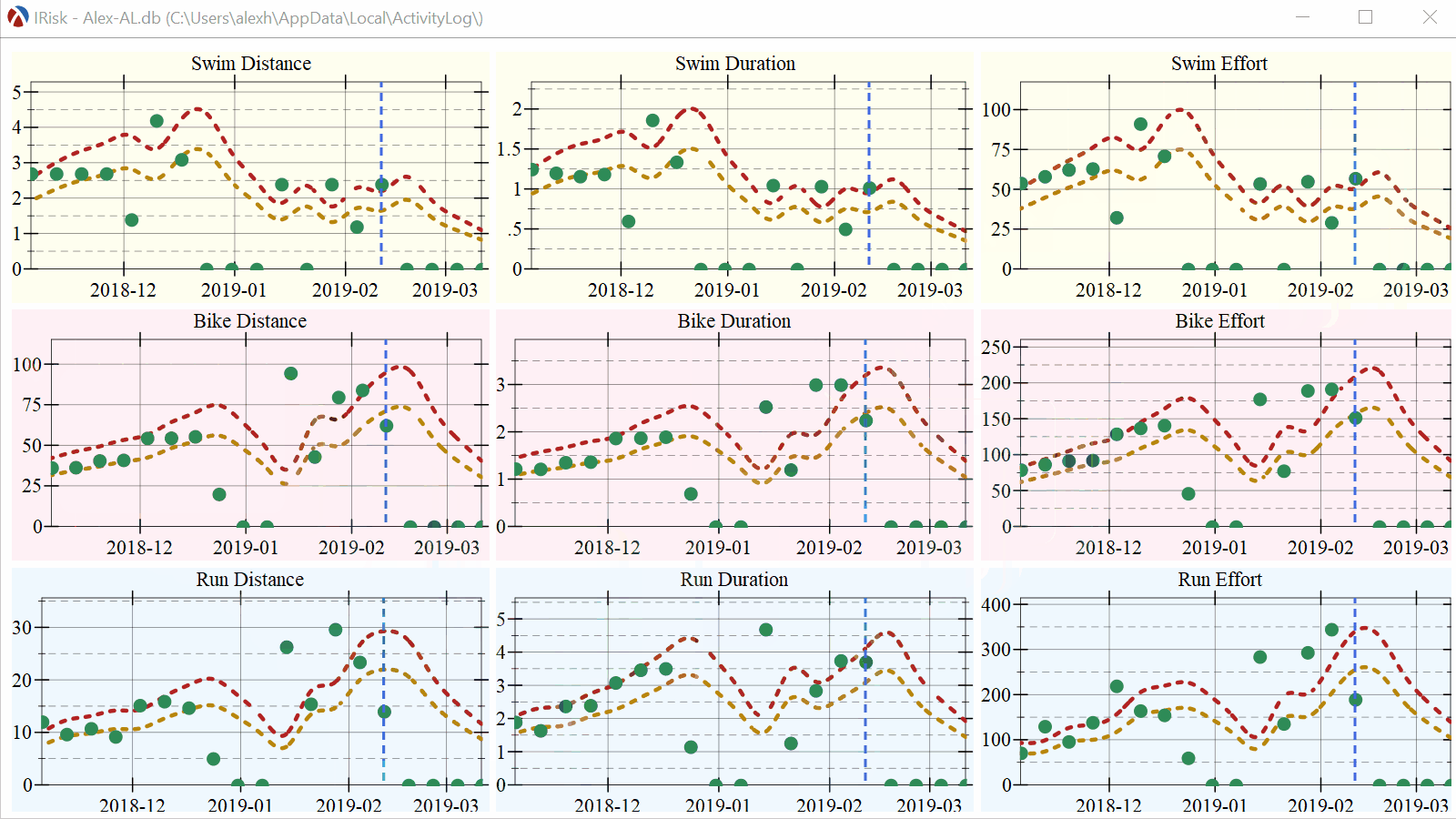
There are nine plots to visualize, because in Triathlon, there are three disciplines, Swimming, Cycling and Running, and we need a plot for each one. Also, the “training load” concept can be measured in terms of distance, duration or “effort” — the last one is a somewhat abstract term indicating how hard an activity was.
Preparing the data
ActivityLog2 stores all data in a SQLite database, so the information we need can be retrieved using an SQL query. As an example, and to keep things simple, the query below retrieves data from for cycling only, but it can be extended to retrieve run and swim columns too:
1 2 3 4 5 6 7 |
select date(VTS.start_time, 'unixepoch', 'localtime', '-6 days', 'weekday 1') as week, round(total(VTS.bike_distance) / 1000.0, 0) as bDist, round(total(VTS.bike_time) / 3600.0, 1) as bDuration, round(total(VTS.bike_effort), 0) as bEffort from V_TRIATHLON_SESSIONS VTS where VTS.start_time > strftime('%s', date('now', '-56 days')) group by week; |
Running the query above, will produces the result below, but there is a problem with it: Even though we asked for 8 weeks worth of data (56 days in the query above), we only got six rows back, with the weeks between 24 December 2018 and 14 February 2019 missing. This is because I did not do any training between those dates, and since no activities are present, there will be no aggregate rows for those weeks in the result set.
sqlite>
week bDist bDuration bEffort
---------- ---------- ---------- ----------
2018-12-17 56.0 1.9 141.0
2018-12-24 20.0 0.7 46.0
2019-01-14 95.0 2.5 178.0
2019-01-21 43.0 1.2 78.0
2019-01-28 80.0 3.0 190.0
2019-02-04 63.0 2.3 132.0One solution is to write Racket code which takes this result set and inserts empty rows for any missing weeks. I tried that first, but the Racket code to do that is surprisingly complex, at least when compared to the SQL solution. The SQL solution involves creates a recursive CTE (common table expression) which generates timestamps for each week between two date ranges and than joins this table with the data from the database. The updated query, as used by the application, is shown below. It has the advantage that it can also generate rows for dates in the future, where no activities have been recorded yet, and this simplifies calculating the training load for future dates.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
with recursive TS(week) as ( select date(?, 'unixepoch', 'localtime', 'weekday 1') as week union all select date(week, '+7 days', 'weekday 1') as week from TS where strftime('%s', week) < strftime('%s', date(?, 'unixepoch', 'localtime', '-6 days', 'weekday 1'))), SE(week, rDist, rDuration, rTss, bDist, bDuration, bTss, sDist, sDuration, sTss) as ( select date(VTS.start_time, 'unixepoch', 'localtime', '-6 days', 'weekday 1') as week, total(VTS.bike_distance) / 1000.0 as bDist, total(VTS.bike_time) / 3600.0 as bDuration, total(VTS.bike_effort) as bTss, from V_TRIATHLON_SESSIONS VTS where VTS.start_time between (select min(strftime('%s', TS.week)) from TS) and (select max(strftime('%s', TS.week)) from TS) group by week) select (strftime('%s', TS.week) + 0) as timestamp, -- +0 forces the column to be an int TS.week as week, coalesce(SE.bDist, 0) as bDist, coalesce(SE.bDuration, 0) as bDuration, coalesce(SE.bTss, 0) as bTss, from TS left join SE on TS.week = SE.week; |
This query is somewhat large, but it illustrates that many complex things can be done in SQL, and these things simplify the processing of the data. Note that the query above accepts two parameters (the question marks, ?), which can be used to supply a date range for which to return data.
Loading the data into a Racket data-frame
With the SQL query ready, we can start working on the Racket code which reads the data. First, we’ll need a connection to the database — in the SQLite case, this is a path to a file and the connection is opened using sqlite3-connect. The database is opened in read-only mode, as we only run queries on it, never update the database.
Next, we’ll need to access the actual SQL query written previously. I prefer to store the SQL query in a separate file and read it in at runtime; the define-sql-statement function is a helper function defined in dbutil.rkt, it reads a SQL query from a file and produces a virtual-statement which can be used as a parameter to all query functions in the db package. There are a few alternatives available: the query could have been stored as a string inside the source code, or defined using one of the Racket packages that define a SQL DSL in the code, but I prefer storing the SQL code separately because I can run it directly in the SQLite command line utility and validate the query results independently from the Racket code.
Lastly, the function fetch-irisk-data will construct a data-frame from the results of running the query. Since the SQL query requires two UNIX timestamps for the start and end of the date range, and UNIX timestamps are difficult to use directly, the function takes two parameters: number of weeks in the past to fetch data from and number of weeks in the future to make predictions and calculates the parameters for the query.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
(define database-file "path-to-database.db") (define db (sqlite3-connect #:database database-file #:mode 'read-only)) (define-runtime-path query-file "./irisk-query.sql") (define irisk-sql (define-sql-statement query-file)) (define (fetch-irisk-data db weeks-back weeks-forward) (define now (current-seconds)) (define df (df-read/sql db (irisk-sql) (- now (* weeks-back 7 24 3600)) (+ now (* weeks-forward 7 24 3600)))) ;; Mark the timestamp series as sorted, so we can do lookups on it. (df-set-sorted df "timestamp" <=) df) |
With only a small amount of code, we can load the data in Racket and start exploring it in the REPL:
> (define df (fetch-irisk-data db 10 4))
> (df-describe df)
data-frame: 11 columns, 14 rows
properties:
series:
NAs min max mean stddev
bDist 0 0 94.66 34.79 34.68
bDuration 0 0 3 1.15 1.15
bTss 0 0 191.8 77.99 77.04
rDist 0 0 20.04 8.83 8.29
rDuration 0 0 4.44 1.46 1.49
rTss 0 0 322.49 115.4 122.29
sDist 0 0 4.2 1.05 1.38
sDuration 0 0 1.87 0.46 0.61
sTss 0 0 91.32 23.79 30.83
timestamp 0 1543795200 1551657600 1547726400 2438026.74
week 0 +inf.0 -inf.0 +nan.0 +nan.0
>The data frame contains a series for each column retrieved by the SQL query, we now need to add the “load” series — for each of the series in the data frame, we’ll add a corresponding load series, containing a smoothed average. add-smoothed-series constructs a single such series, while add-all-smoothed-series creates all the load series:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
(define (add-smoothed-series df base-series load-series factor) (define smoothed 0) (df-add-derived df load-series ; series name to create (list base-series) ; selected series (lambda (l) ;; 'l' is a list containing a "row" of the selected series, since we only ;; select one series (base-series), the list contains one element, which ;; we extract here: (define value (list-ref l 0)) ;; this weeks volume contributes to next weeks load, so we return the ;; previous smoothed value (`begin0`) and computing the next one. (begin0 smoothed (set! smoothed (+ (* (- 1 factor) smoothed) (* factor (or value 0)))))))) (define (add-all-smoothed-series df factor) (add-smoothed-series df "sDuration" "sDurationLoad" factor) (add-smoothed-series df "sDist" "sDistLoad" factor) (add-smoothed-series df "sTss" "sTssLoad" factor) (add-smoothed-series df "bDuration" "bDurationLoad" factor) (add-smoothed-series df "bDist" "bDistLoad" factor) (add-smoothed-series df "bTss" "bTssLoad" factor) (add-smoothed-series df "rDuration" "rDurationLoad" factor) (add-smoothed-series df "rDist" "rDistLoad" factor) (add-smoothed-series df "rTss" "rTssLoad" factor)) |
Plotting the data
With the data ready, we can start exploring it in the DrRacket REPL. For example, to plot the weekly bike durations and the duration load, we can type the following in DrRacket:

While the above plot was simple to generate, it is not very attractive and does not present the information in a useful way. There are several ways to improve this plot, below are some of the things that can be easily done to improve its appearance.
The default colors used by the plot library are very basic, but the racket/draw package provides a color database which allows selecting nice colors by their names:
1 2 3 4 5 |
(define dot-color (send the-color-database find-color "SeaGreen")) (define warning-color (send the-color-database find-color "DarkGoldenrod")) (define danger-color (send the-color-database find-color "Firebrick")) (define bike-bg-color (send the-color-database find-color "LavenderBlush")) (define this-week-color (send the-color-database find-color "RoyalBlue")) |
By default, the plot package calculates the limits of the plot so that all the data fits snuggly on the plot area, this however makes places some of the dots at the edge of the plot area, making them difficult to see. We can calculate the upper limit limit of the plot using the df-statistics function and increase it slightly:
The line for the “load” series has several edges, as there is one data point for each week, we can smooth it out using the spline function (part of the data-frame package). While doing it we can actually plot two lines: a “warning” line at 20% increase of the load and a “danger” line t 60% increase of the load:
Given that some of the data is in the past, and some is in the future, we can plot a vertical rule where the current week is. To find the X value of the current week, we can use df-index-of and df-ref:
1 2 |
(define now-index (df-index-of df "timestamp" (current-seconds))) (define now-value (df-ref df (max 0 (sub1 now-index)) "timestamp")) |
Finally, we can use plot parameters to make the X axis a date axis, instead of printing integer values for the UNIX timestamps, plus we can add a title and clear the labels for the X and Y axis (their meaning should be obvious and allows for a more compact plot)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
(parameterize ([plot-title "Bike Duration"] [plot-background bike-bg-color] [plot-x-ticks (date-ticks)] [plot-y-label #f] [plot-x-label #f]) (plot-snip (list (tick-grid) (function warning-line #:color warning-color #:width 3 #:style 'dot) (function danger-line #:color danger-color #:width 3 #:style 'dot) (points data #:sym 'fullcircle #:size (* (point-size) 1.5) #:fill-color dot-color #:color dot-color) (vrule now-value #:color this-week-color #:width 2.0 #:style 'short-dash)) #:y-min 0 #:y-max (max max-y 1))) |
And here is the same data, this time plotted with all the enhancements discussed above:

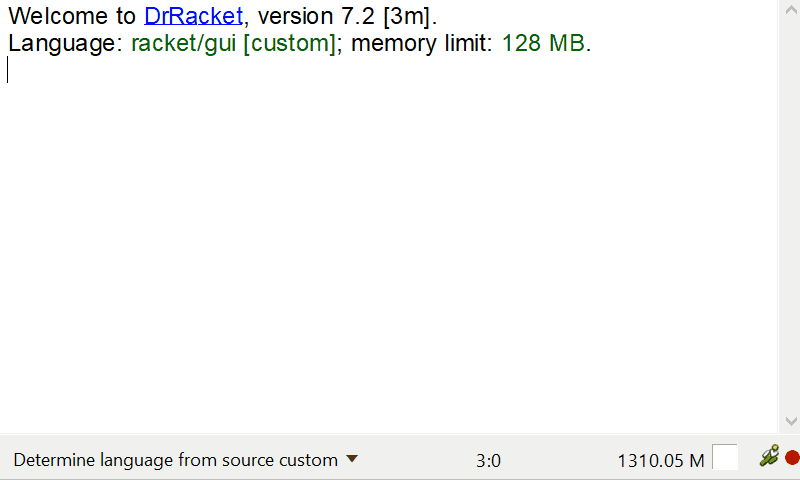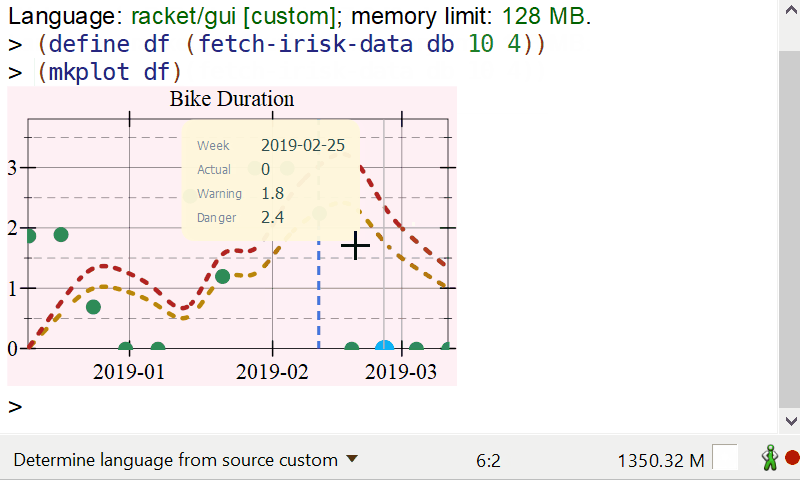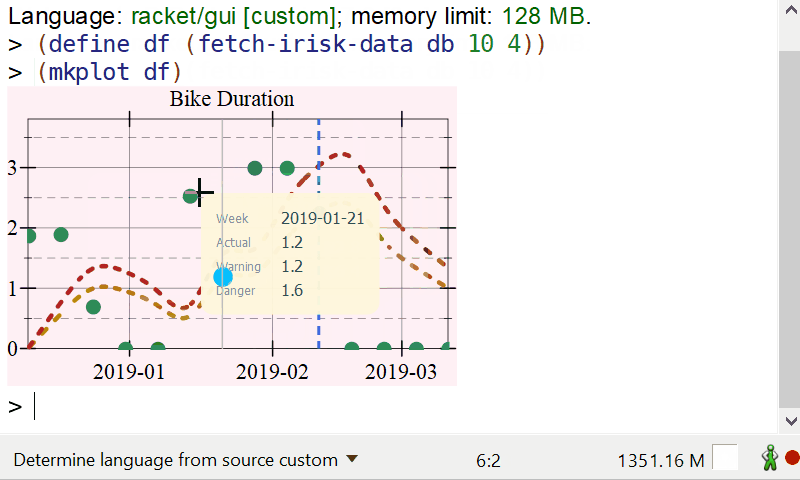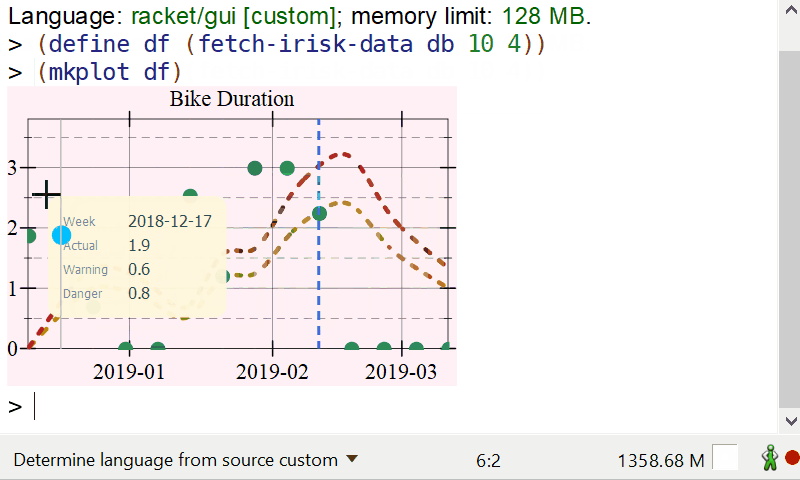
Interactive info display on mouse hover
There is a lot of data available to display, but showing it on the plot would result in a lot of clutter. We can, however, add a hover callback which can display information about the week where the mouse pointer is. The plot, or plot-snip functions produce a snip% object, rather than an image, and snips are interactive objects which DrRacket knows how to manage. The plot snips support a “hover callback” which is a callback invoked whenever the mouse is over the plot area. This callback can than add further elements to the plot. You can read more about interactive plots here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
(define (format-value x) (~r x #:precision 1)) (define (hover-callback snip event x y) (define renderers '()) (define (add-renderer r) (set! renderers (cons r renderers))) (when (and snip x y event) ;; Find the position of the mouse in the current data frame, extract the ;; information for the current location and display a vertical line plus ;; a pict containing information about the plot. (define index (df-index-of df "timestamp" x)) (when (and index (< index (df-row-count df))) (define ts (df-ref df index "timestamp")) (define week (df-ref df index "week")) (define vol (df-ref df index "bDuration")) (define vol-warning (warning-line ts)) (define vol-danger (danger-line ts)) (add-renderer (vrule ts #:width 1.0 #:color "gray")) (add-renderer (points (list (vector ts vol)) #:sym 'fullcircle #:size (* (point-size) 2.0) #:fill-color hl-dot-color #:color hl-dot-color)) (define badge (make-hover-badge (list (list "Danger" (format-value vol-danger)) (list "Warning" (format-value vol-warning)) (list "Actual" (format-value vol)) (list "Week" week)))) (add-renderer (pu-label x y badge)))) (send snip set-overlay-renderers (if (null? renderers) #f renderers))) |
The function above makes use of two utility functions defined in plot-util.rkt, make-hover-badge creates a pict with the label to display, and pu-label creates a render which will show up on the plot.
The hover-callback can be installed in the plot snip after it was created but before returning it to DrRacket for display:
Creating a standalone application
Exploring plots in the interactive DrRacket REPL is what makes Racket powerful and attractive to use, it is however inconvenient to start DrRacket and produce these plots manually every time I want to look at the data. Fortunately, it is easy to build a standalone GUI application to show these plots in a window, so I can simply have a link on my desktop to start it up and look at the plots.
The plot snips which are displayed in the DrRacket REPL can also be used directly inside an editor-canvas% (including the mouse-hover functionality). It is somewhat complex to use an editor-canvas% for this purpose, I plan to write blog post on this subject, but for now, you can have a look at the plot-container.rkt file for the implementation — this is a class which allows packaging multiple plots in a canvas, handling the layout and resize for them. The plots are created identically — there is a function which is passed in the series to plot, plus some additional data, and they are added to this canvas.
This is a basic GUI application (at least as far as the GUI part goes), but there are a few tricks and techniques which makes the application easier to use.
Finding the location of the database
The application needs access to the ActivityLog2 database, and its location is stored in the ActivityLog2 preferences file. Racket provides a mechanism for storing and retrieving key-value pairs into a file using the put-preferences, get-preference functions. Simple wrappers around these functions (called get-pref and put-pref), which change the default setting file, allows storing per-application information. Finding the location of the database, is a simple matter of knowing which key it is stored under:
The application is set up to always open the database file that was last opened in ActivityLog2. There is also some code to handle the case where no database file is present — this simply displays an error message.
Restoring the window size
Well behaved applications will remember their settings even after they are closed and reopened. For this application, there are not many settings, but the size of the window is one of them — rather than having a fixed window size, the application will save its window size in the preferences file on exit and restore it when it is reopened. This way, I can resize the application to the size I want and this size will be remembered when I reopen the application.
Restoring frame dimensions is simple, they are retrieved from the preference file, with some suitable defaults if they don’t exist, than the frame is created with these dimensions:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
;; retrieve previous dimensions and maximized flag (define dims (get-pref 'irisk-dashboard:frame-dimensions (lambda () (cons 1200 750)))) (define maximized? (get-pref 'irisk-dashboard:frame-maximized (lambda () #f))) (define tl (new (class frame% (init) (super-new) (define/augment (on-close) (send this show #f) (on-toplevel-close this))) [label "AL2 IRisk Dashboard"] [width (car dims)] [height (cdr dims)])) ;; maximize the frame if it was maximized last time (when maximized? (send tl maximize maximized?)) |
To save the dimensions on exit, the on-close method in the frame% class is overridden, to call on-toplevel-close, which is defined below — this functions saves the current dimensions into the preferences file:
Avoiding flickering plots
A windows dimensions are only computed when the window is shown and this means that plot snips will not know their size until the window is shown. If they are created and added to the container before the container is shown, they will be shown as the wrong size, showing an ugly redraw as they are resized. This situation can be avoided by delaying the creation of the plots until the canvas is shown, by overriding the on-superwindow-show method to call on-canvas-show, which will query the canvas size and create the plots at their correct dimensions:
Building an executable and a distribution
Racket allows building stand-alone executables, which are applications that will run on systems that don’t have Racket installed. There are several ways to create executables: from the DrRacket GUI, from another racket program using the compiler/embed module, or from the command line using raco. To create an executable from the command line, you can use the command:
raco exe --gui --embed-dlls -o AL2-IRisk.exe main.rktThe resulting executable will however still reference some files in the source directory. In our case, this is the SQL query that was used to retrieve the data. It is possible to tell Racket to create a distribution, which is a directory containing the executable, plus any files it references using define-runtime-path, to the resulting application is truly standalone. The command below will package the executable and the SQL query in the “AL2-IRisk” folder, which can than be installed independently of Racket:
raco distribute ./AL2-IRisk AL2-IRisk.exeConclusion
This application is a prototype, and you can find the full source here. I will use it for a while, tweaking a few things as I continue to use it and have more experience with the data. If this proves to be a good idea, the code will be added to ActivityLog2 and this prototype discarded — this is what prototypes are for. If it turns out that it is not very useful information, it is no big loss, as it did not take too long to write and this is the advantage of prototypes. In fact, this blog post has more lines than the actual application, and it also took longer to write.