Racket Data Frame Package
A Racket implementation of a data frame structure, which allows efficient manipulation of data that is organized in rows and columns. It was originally written as part of the ActivityLog2 project, than moved into its own Racket package.
You can install the package using raco pkg install data-frame, browse the reference documentation or visit the project page on GitHub. The examples below illustrate some more complex things that can be done with this package.
The data-frame package was developed to help analyzing fitness data recorded by Garmin devices. A fitness device, such as a bike computer or a running watch, will usually record data at 1 second interval. Each recording will contain information about the speed, GPS position, heart rate, cadence, power and several other parameters. A 2 hour bike ride will contain 7200 such data points and each data point will contain up to about 40 measurements. Someone serious about training will record more than 200 such activities each year. The size of this data set requires some careful thought about how to keep data in memory so it can be analyzed and visualized efficiently, and the data frame representation came out of this requirement.
Data frame object overview
The data in the data-frame object can be viewed as a 2 dimensional table with rows and columns. Each column is called a “series”, which consists of a name and the actual data. The package contains operations for selecting subsets of the data, both on rows and columns, efficient search and indexing, plus helper functions to calculate statistics values and generate various plots.
The following examples are from the ActivityLog2 application and all use a data frame loaded for a session, however data can also be loaded into the data frame from SQL databases using df-read/sql or from CSV files using df-read/csv. The following prelude is assumed, which will load the data frame for session id 1816 from the default database:
A simple way to get an overview of the contents of the data frame is the df-describe function, which shows all series in a data frame and some statistics values about each of them:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
scratch.rkt> (df-describe df) data-frame: 39 series, 4882 items properties: is-lap-swim? #f session-id 1816 sport #(2 #f) stop-points (1480802649 1480803106 1480804370 1480805370) weight-series timer laps #(1480802483 1480802896 1480803311 1480803693 1480804096 14808 series: NAs min max mean stddev alt 0 -5.4 38.8 10.89 9.21 cad 32 0 114 73.21 23.86 calt 0 0.1 44.05 16.66 9.28 distance 0 0 36.17 18.42 10.54 dst 0 0.9 36171.06 18417.2 10535.92 elapsed 0 0.5 4950.5 2491.93 1426.36 grade 10 -38.38 18.26 0.45 3.19 hr 0 91 169 144.02 12.28 ### MANY OTHER SERIES OMITTED ### timestamp 0 1480802483.5 1480807433.5 1480804974.93 1426.36 scratch.rkt> |
Working with properties
A data frame object can store properties, which are simple key value pairs. In ActivityLog2 these are used to store such things as the sport type, session it and lap timestamps, but they can be used to store any data about the series in the data frame
get-property-names— returns a list of property names stored in the objectput-property,get-property— are used to set and retrieve properties
1 2 3 4 5 6 7 8 |
scratch.rkt> (df-property-names df) '(is-lap-swim? session-id sport stop-points weight-series laps) scratch.rkt> (df-get-property df 'session-id) 1816 scratch.rkt> (df-put-property df 'test-property 'hello) scratch.rkt> (df-get-property df 'test-property) 'hello scratch.rkt> |
Working with series names
The following functions can be used to get information about what series are available in the data frame:
df-series-names— returns a list of all the series namesdf-contains?— returns #t if the data frame contains all of the specified seriesdf-contains/any?— returns #t if the data frame contains any of the specified seriesdf-row-count— returns the number of elements in each series of the data frame (all series have the same number of elements)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
scratch.rkt> (df-series-names df) '("timer" "lpsmth" "rpppa" "rpps" "rppa" "hr" "lon" "lteff" "calt" "lat" "lppps" "lppa" "lppe" "elapsed" "pwr" "dst" "rpppe" "grade" "hr-zone" "lpps" "lpppe" "stride" "spd" "speed" "distance" "pwr-zone" "timestamp" "alt" "rpsmth" "lrbal" "pace" "cad" "rteff" "rppe" "rpco" "rppps" "hr-pct" "lpppa" "lpco") scratch.rkt> (df-contains? df "timer") #t scratch.rkt> (df-contains? df "lat" "lon") #t scratch.rkt> (df-contains? df "non-existent") #f scratch.rkt> (df-contains? df "timer" "non-existent") #f scratch.rkt> (df-contains/any? df "timer" "non-existent") #t scratch.rkt> (df-row-count df) 4882 |
Accessing the data using df-select and df-select*
The df-select and df-select* functions can be used to retrieve data from a data frame. The simplest method, is to just ask for the entire series. The following retrieves the entire set of heart rate values:
1 2 |
scratch.rkt> (df-select df "hr") '#(89.0 93.0 94.0 94.0 94.0 ...) |
Data can also be filtered. For example, the following retrieves only heart rate values greater than 150 BPM:
Finally, a subset of the data points can be retrieved by specifying start and end indexes (see below on how to retrieve useful indexes):
1 2 |
scratch.rkt> (df-select df "hr" #:start 100 #:stop 105) '#(123.0 122.0 123.0 123.0 123.0) |
The df-select* function can be used to retrieve data from multiple series. It will return a vector containing a vector for each data point selected. For example, the code below can be used to retrieve the GPS track from a data series:
1 2 3 4 5 6 7 8 |
scratch.rkt> (df-select* df "lat" "lon" #:filter valid-only) '#(#(-22.475327365100384 118.560850918293) #(-22.475248826667666 118.5613826662302) #(-22.475329376757145 118.56146103702486) #(-22.475371956825256 118.56151258572936) #(-22.475371873006225 118.56151392683387) #(-22.475372292101383 118.56153203174472) ...) |
Find positions using df-index-of and df-index-of*
The df-index-of and df-index-of* functions can be used to find the position where a value is stored in a data series — the data series will have to make sorted for this to work using df-set-sorted. df-index-of retrieves a single position, while df-index-of** retrieves multiple values at once.
The laps property contains a list of timestamps for the start of each lap in the activity:
1 2 3 4 |
scratch.rkt> (df-get-property df 'laps) '#(1480802483 1480802896 1480803311 1480803693 1480804096 1480804492 1480804870 1480805324 1480805750 1480806117 1480806508 1480806929 1480807412) |
Find the position where the second and third laps start:
1 2 3 4 5 6 |
scratch.rkt> (df-index-of df "timestamp" 1480802896) 392 scratch.rkt> (df-index-of df "timestamp" 1480803311) 785 scratch.rkt> (df-index-of* df "timestamp" 1480802896 1480803311) '(392 785) |
Extract heart rate data or the GPS track for the second lap:
The same mechanism can be used to find the positions for distances, or time, etc. For example we could look up in the “dst” series the positions for the second KM in the activity. The returned positions could be used to retrieve the GPS track for the second KM of the activity:
1 2 |
scratch.rkt> (df-index-of* df "dst" 1000 2000) '(131 271) |
Retrieving individual values using df-ref and df-ref*
The df-ref and df-ref* functions can be used to retrieve a single value from an index in a series or in multiple series (df-ref*). Using the examples above, to retrieve the heart rate at the start of the second lap:
1 2 |
scratch.rkt> (df-ref df 392 "hr") 157.0 |
And to retrieve the GPS location where the second lap starts:
1 2 |
scratch.rkt> (df-ref* df 392 "lat" "lon") '#(-22.475329376757145 118.56146103702486) |
NOTE unlike the df-index-of, df-index-of* functions, the df-ref and df-ref* methods have the index specified before the series names.
Lookups using df-lookup and df-lookup*
The df-index-of and df-ref functions can be combined into a single function, df-lookup, which can be used to lookup a value in a base series and return the corresponding value in a second series. Continuing the example above, the heart rate for the start of a lap can be retrieved using a single call:
1 2 3 4 |
scratch.rkt> (df-lookup df "timestamp" "hr" 1480802896) 157.0 scratch.rkt> (df-lookup df "timestamp" '("lat" "lon") 1480802896) '#(-22.475329376757145 118.56146103702486) |
Multiple values can be looked up using df-lookup*, which is analogous to df-index-of*:
1 2 |
scratch.rkt> (df-lookup* df "timestamp" "hr" 1480802896 1480803311) '(157.0 133.0) |
Iterating over values using df-map, df-for-each and df-fold
The df-map, df-for-each and df-fold functions are similar to the corresponding Racket built-in variants, but operate on the values of series. They take the following parameters:
base-seriesis either a series name or a list of series names. The iteration will happen over values in these seriesinit-val(used forfoldonly) is the initial value passed infnis a function called on each value.#:startand#:stopallow specifying start and end positions for elements that are iterated.
The call back function can have one or two arguments for df-map and df-for-each and two or three arguments for df-fold.
To iterate over a single value at a time, use a function like (lambda (VAL)
...), it will be passed in values from the series packed in a vector. To iterate over adjacent pairs of values, specify (lambda (PREV-VAL VAL) ...), it will be passed in the current and previous set of values. The variants used for fold use the accumulator as a first argument: (lambda (ACCUM VAL)
...), or (lambda (ACCUM PREV-VAL VAL) ...).
For example, the following function can be used to calculate the work (in Joules) from the time and the power series. The function receives pairs of data points and determines the amount of work (power * delta-time) and adds it to the accumulated value:
1 2 3 4 5 6 7 8 9 10 11 12 |
(define (accum-work prev-work prev-val val) ;; for the first element, there will be no previous value (if prev-val (match-let (((vector time1 power1) prev-val) ((vector time2 power2) val)) (if (and time1 power1 time2 power2) ; all values are valid (+ prev-work (* (* 0.5 (+ power1 power2)) (- time2 time1))) prev-work)) prev-work)) scratch.rkt> (df-fold df '("timer" "pwr") 0 accum-work) 796091.0 |
Adding new series using df-add-derived and df-add-lazy
The df-add-derived function can be used to add new series to the data frame, as computations from other series. It is used in session-df for example to create a “distance” series (which is either in KM or Miles") from the “dst” series which is in meters.
The function takes the following parameters:
name— name of the new data seriesbase-series— is either a series name or a list of series names. The iteration will happen over values in these seriesvalue-fn— function to produce values for the new series it has the same signature as the function passed tomaporfor-each
The example below, adds the accumulated work at each point in the bike ride:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
(define current-work 0) (define (add-work prev-val val) ;; for the first element, there will be no previous value (when prev-val (match-let (((vector time1 power1) prev-val) ((vector time2 power2) val)) (when (and time1 power1 time2 power2) ; all values are valid (set! current-work (+ current-work (* (* 0.5 (+ power1 power2)) (- time2 time1))))))) current-work) scratch.rkt> (df-add-derived df "work" '("timer" "pwr") add-work) scratch.rkt> (df-select df "work") '#(0 0.0 0.0 0.0 50.0 241.5 553.0 891.5 1208.0 1439.0 ... 796091.0) |
The df-add-lazy is the lazy version of the function: it adds a closure to the data frame and the data series will be created the first time it is referenced. Special care needs to be used with this function, especially if it captures local variables, as the environment in which the function runs might not be the same as the non-lazy version.
Other functionality
The package also contains functions that provide additional functionality:
- statistics on data frame objects can be calculated using
df-statisticsanddf-quantile, these adapt the functions frommath/statisticsto work directly with data frames - histograms and histogram plots can be computed using
df-histogramandhistogram-renderer(plus some other functions) - various helpers for creating scatter plots, see
scatter-rendererand related functions.
Least Squares Fitting
The df-least-squares-fit function can be used to find a best fit function for some data in the data frame. It can find polynomial, exponential, logarithmic and power functions which closely match an input data set. To use it, you will need to specify the X and Y series names:
1 2 |
(define fit (df-least-squares-fit df "xseries" "yseries" #:mode 'polynomial #:polynomial-degree 2)) |
The resulting fit object acts as a function, so it can be plotted together with the input data set:
1 2 3 4 5 |
(plot (list (tick-grid) (points (df-select* df "xseries" "yseries")) (function fit))) |
Here are some examples of fitting different data sets:






Re-working the map widget demo to use data frames
The map-widget demo used a small library to load a GPX file containing the track that is shown on the map, but with the data-frame library this is supported directly.
The example below uses the following racket file as the base. This file is evaluated and the rest of the commands can be typed in at the prompt:
A GPX file can be loaded in a data frame using df-read/gpx, and the resulting data frame can be inspected using df-describe:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
df-demo.rkt> (define df (df-read/gpx "./tarn-shelf.gpx")) df-demo.rkt> (df-describe df) data-frame: 5 columns, 16287 rows properties: waypoints ((1485442935 -42.67913189716637 146.58711176365614 1126.94 Lap 1) laps (1485442935 1485444483 1485445975 1485447502 1485449146 1485450523 name Tarn Shelf, Mt Field NP (Hiking) series: NAs min max mean stddev alt 0 854.93 1278.35 1089.94 122.06 dst 0 0 14903.55 7184.98 4192.82 lat 0 -42.69 -42.65 -42.67 0.01 lon 0 146.56 146.59 146.58 0.01 timestamp 0 1485470647 1485490648 1485480878.4 5984.35 df-demo.rkt> |
The data from the GPX file is loaded into 5 series containing the latitude, longitude, elevation and timestamp for each point. In addition, a distance series, “dst” is added representing the distance of each point from the start of the track, this will allow us to look up GPS positions based on distance.
The GPX track can be added to the map widget by selecting just the “lat” and “lon” using df-select*. You might need to center the map, to move it to the location where the track is using the center-map method of the map widget:
To put marker locations on the map, we need to find the GPS location of each mile. The df-lookup function can be used to find an element in a target series given a value in a source series, for example, the call (df-lookup df
"dst" '("lat" "lon) 1609) will return the GPS coordinates for the position at the first mile1 in the track. To find all the mile locations we can use a for loop:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
df-demo.rkt> (define total-distance (df-ref df (sub1 (df-row-count df)) "dst")) df-demo.rkt> total-distance 14903.545661638052 df-demo.rkt> (define marker-locations (for/list ([mile (in-range 0 total-distance 1609)]) (df-lookup df "dst" '("lat" "lon") mile))) df-demo.rkt> marker-locations '(#(-42.68540868535638 146.59324564039707) #(-42.67952333204448 146.58431304618716) #(-42.67874247394502 146.57109302468598) #(-42.67064957879484 146.5663103107363) #(-42.65975930728018 146.56189740635455) #(-42.65489989891648 146.57579275779426) #(-42.65118286013603 146.58114535734057) #(-42.65805283561349 146.58975390717387) #(-42.67057556658983 146.59253066405654) #(-42.68192206509411 146.5928765013814)) |
Finally, the markers can be added to the map using the add-marker method on the map widget:
And this produces the following result:
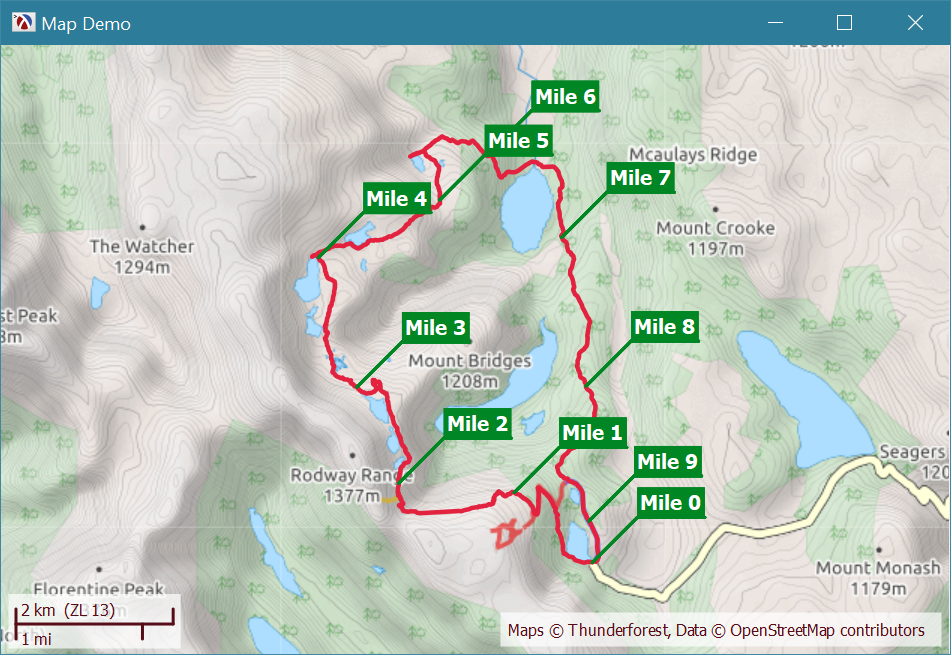
An interactive elevation plot can also be added, and the data frame functions df-select*, df-lookup and, a more appropriate df-lookup/interpolated can be used to simplify the code. The entire example is available in this GitHub Gist.
Footnotes
-
the “dst” series is in meters, so the first mile is at 1609 meters ↩